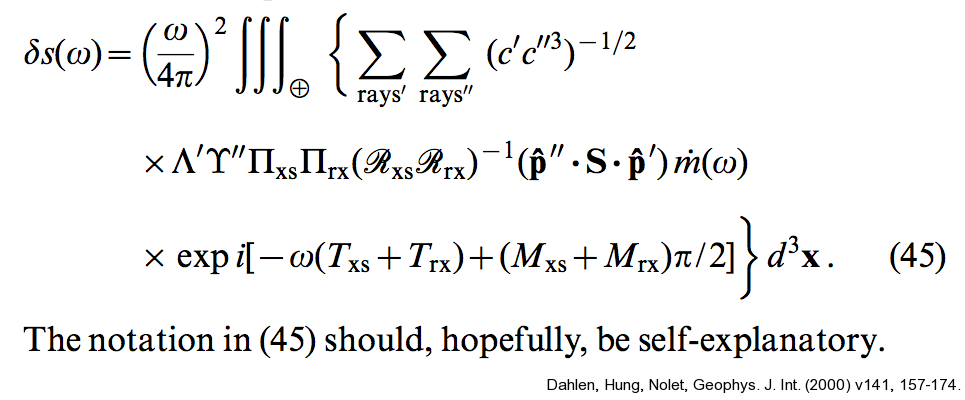If you frequently program and run computations on a remote Linux/Unix computer, maybe you're familiar with this scenario that I often find myself in: Working in six different terminal logins to the remote computer from the office desktop computer, cranking up long-running computations that are still not finished and are outputting important information (calculation status or results), but it's time to catch the bus home. On the bus I realized I started one of the computations with a wrong parameter, so I login from my iPhone to fix and restart it, but I have to setup the whole environment again (cd, restart octave, load data or scripts etc) in this new login. Then I get home and later after the wife and kids are in bed I'm logging in again... and have to set up the whole environment again with my new set of six logins. And the following morning when I come back to the office the same thing happens.
Enter the long-existing and very simple, but totally indispensable GNU
screen command. It's maybe a bit similar to
emacs (if you're familiar with that all-but-kitchen-sink text editor), in terms of letting you set up different tiled windows and buffers and shells that you can rearrange and swap between; maybe a bit more of a
vi style to it than an
emacs style. But the real key is its ability to let you completely
detach the entire thing from one terminal and
reattach it intact from a different terminal login. As far as I know, that's something that
emacs can't do! So imagine I've got an emacs-like setup with six (or whatever) window buffers in some kind of container, and when I go login on the bus from my iPhone I call up that container to my iPhone screen, and when I login from my computer at home I pull the container to that login terminal, and then the next morning pull it back up on my office computer. All the window buffers are still intact the whole time so I don't have to worry about elaborate background-writing-stdout-to-status-files if I don't want to bother.
There are man pages and instruction pages all over the web for it, so I won't bother with that here, but here's
one of the instruction webpages that I found handy when getting started.
Something that isn't so obvious when getting started is how to set up your status line at the bottom of the window, which shows e.g. which window buffers you have, which currently holds the cursor, and whatever else you put in there like time or system load. I'd start with putting the following cryptic lines in your
~/.screenrc file (which I use for my own status line) and start playing from there, probably also referencing a webpage such as
this one.
caption splitonly "%{= ky}%H-%n (%t)"
hardstatus on
hardstatus alwayslastline
hardstatus string "%{.kr}%-w%{.ky}%n-%t%{.kr}%+w %75=%{.kg}%H load: %l" # sysload but no time/date
#hardstatus string "%{.kr}%-w%{.ky}%n-%t%{.kr}%+w %35=%{.kg}%H load: %l %{.kc}%=%c %{.km}%D %d %M %Y" # sysload + time/date
Here's an example of what a screen session might look like on my computer - six logins but only two presently showing:
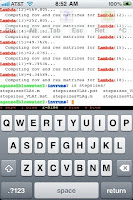
And here's what it looks like on my iPhone in the TouchTerm app:
I tell you, this command totally saves my sanity during weeks when I have to focus on cranking out calculations on our computer cluster.
Just lastly, a handy thing to be aware of regarding GNU screen is that for some reason a number of distros of screen don't have the vertical window split (as compared to the horizontal split seen above) compiled in. It's a handy feature, and here's a
webpage that explains how to patch screen's source code and recompile to get that feature.